以谷歌 PaLM-E 为里程碑,机器人类人操作领域诞生了一系列全新的 AI 方法。这段时间以来,各大公司和高校又不断贡献了创新的训练思路,今天总结几个当下主流方法。 从终局来看,哪种训练方法会成为主流,今天还不好下结论。短期内,大概率各路径会mix together,即各家公司融合多种训练方法,互补数据,最终找到最适合自己业务场景的 AI 路径。 下文重点介绍以下4路径,从最传统到最前沿排序为:
以下为各路径优势劣势一览表: 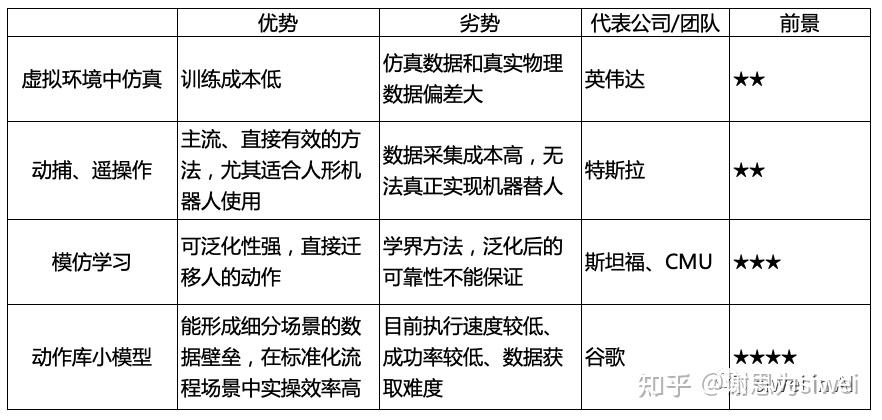 1. 虚拟环境中仿真(sim2real)代表公司:英伟达 优势:训练成本低 劣势:仿真数据和真实物理数据偏差大 英伟达于 ITF World 2023 展示了几条具身智能的落地思路,包括机器人训练、自动驾驶、更智能的语音助手。  其中,多模态具身AI系统 Vima 是英伟达 2022 年底与斯坦福李飞飞合作的研究成果 (https://vimalabs.github.io)。该模型基于transformer,输入自然语言、或自然语言+图片、或自然语言 + 视频序列,完成仿真控制。 但这一成果暴露的局限性在于,机器人只做拾取和放置任务太简单,且仿真环境下的被操作对象非常清晰,不能保证真实环境中成功率。 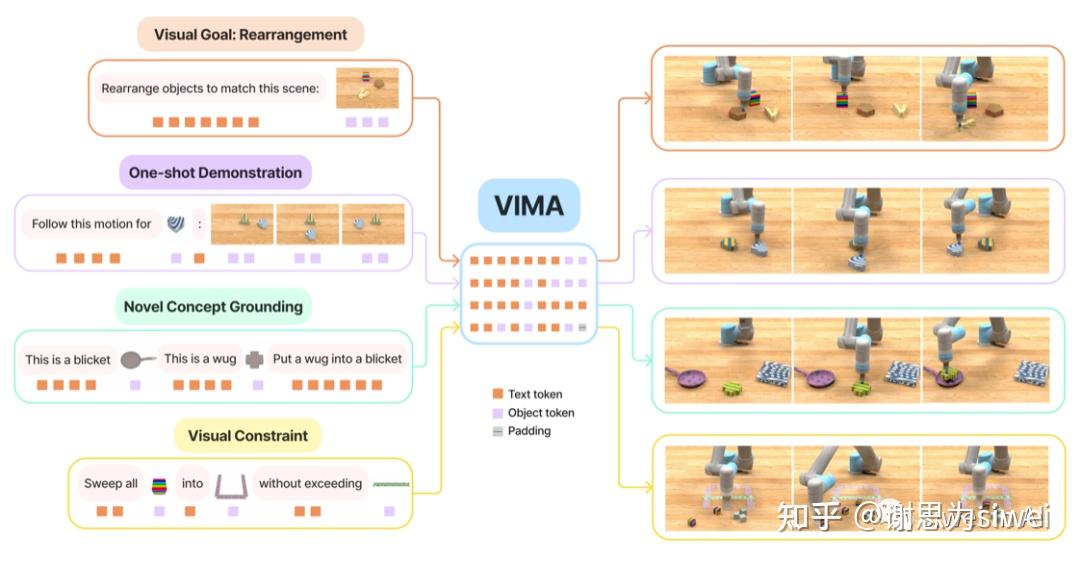 除了机械臂,灵巧手也有类似的训练方法。前段时间于伦敦举办的机器人顶会 ICRA 上,也有团队展示了在虚拟环境中训练灵巧手、采集数据。 他们为 ShadowHand 生成了大规模仿真数据集 DexGraspNet,包含133类5355个物体的132万抓取数据,在数量和质量上优于现有灵巧手抓取数据集。 2. 动捕、遥操作(tele-operation) 通过VR+动捕设备,将人的动作直接迁移到机器人身上。本届 ICRA 机器人顶会上,也多次出现了这一方法。 代表公司:Tesla等多家人形机器人公司、腾讯Robotics X 优势:相对主流、直接有效的方法,尤其适合人形机器人使用 劣势:数据采集成本高,需要真人实时控制,无法真正实现机器替人   不只是双足,四足机器人也可以使用此方法。腾讯 Robotics X 最近发布了基于真狗的动捕思路,可以看到四足机器人明显的运动能力提升。  步骤如下: Step1:动捕采集真狗运动数据; Step2:虚拟环境下训练;学习策略层面知识的网络参数,增加思考、判断能力; Step3:实现灵巧的运动能力、更强的决策力。  3. 模仿学习(mimic play)真人在机器人面前演示动作,机器人观察后,直接迁移到自己本体上完成任务。 代表公司/团队:英伟达、斯坦福、CMU  优势:可泛化性强,最适合家用场景,直接迁移人的动作,例如打开抽屉、拧开瓶盖这种零散动作,将不需要逐一为机器人编程。 劣势:学界诞生的方法,科研团队仅试验过少量简单、家用场景,泛化后的可靠性不能保证。 英伟达+斯坦福论文:MimicPlay: Long-Horizon Imitation Learning by Watching Human Play https://mimic-play.github.io CMU论文:Human-to-Robot Imitation in the Wild https://human2robot.github.io  像婴儿学习走路一样,这一模型会先将人类四肢动作、躯干动作抽象出来,配合观察被操作物体的移动方式,再投射到机器人本体上。 计算机械臂、夹爪、底盘应当如何配合,再通过反复与物体交互,最终实践出适应于该种本体形态的机器人控制模式。 4. 积累机器人动作库,大模型调度小模型(VLM, visual language model) 代表公司:Google Everyday Robot / Google Deepmind 优势:能形成细分场景的数据壁垒;动作库积累后,无需反复训练,在标准化流程场景中实操效率高。 这是机器人领域最前沿的训练方法,也是和大模型时代融合最深入的。Google 的训练进展尤其值得关注,除了较早之前发布的Say-Can、PaLM-E,在刚刚过去的2-3周,该团队也发表了一系列训练上的思路迭代,很值得参考:Reward Translator、RoboCat。 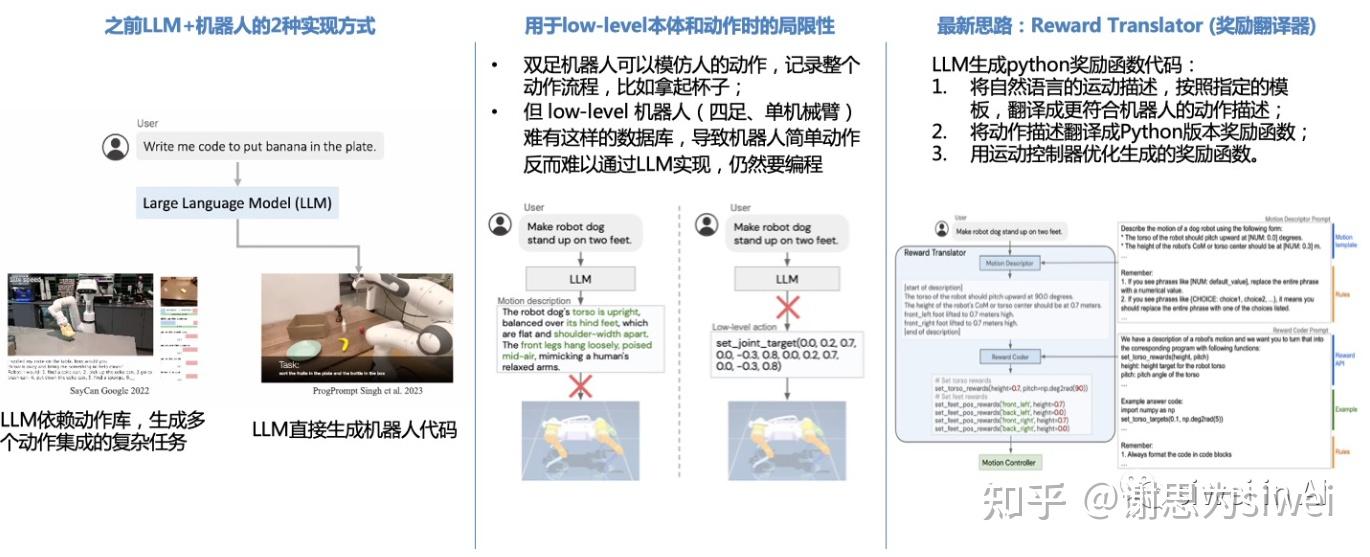  风险和难点:
- ToB路线,Tesla可以在自家工厂任意收集生产数据,但如果是第三方智能机器人提供商,要如何界定可收集生产数据的维度?工厂和流水线大概率很难允许数据出厂,那是否存在换个客户,就要重新fine-tune一套小模型的商务难点? 最后,在大小模型耦合的技术路径上,创业公司未来的核心竞争力可能在于:针对场景,开发自己的小模型动作库,形成数据壁垒。 |
 |Archiver|手机版|小黑屋|软件开发编程门户
( 陇ICP备2024013992号-1|
|Archiver|手机版|小黑屋|软件开发编程门户
( 陇ICP备2024013992号-1|![]() 甘公网安备62090002000130号 )
甘公网安备62090002000130号 )
GMT+8, 2025-5-15 13:51 , Processed in 0.038577 second(s), 16 queries .
Powered by Discuz! X3.5
© 2001-2025 Discuz! Team.





